Istanbul Technical University
Signal Processing for Computational Intelligence Group
Our Mission
At SP4CING, we are developing signal processing techniques for various computational intelligence applications, ranging from environmental monitoring to bio-image analysis. We are part of Informatics Institute, İstanbul Technical University. For further information, please contact us
Small Object Detection in Aerial Images
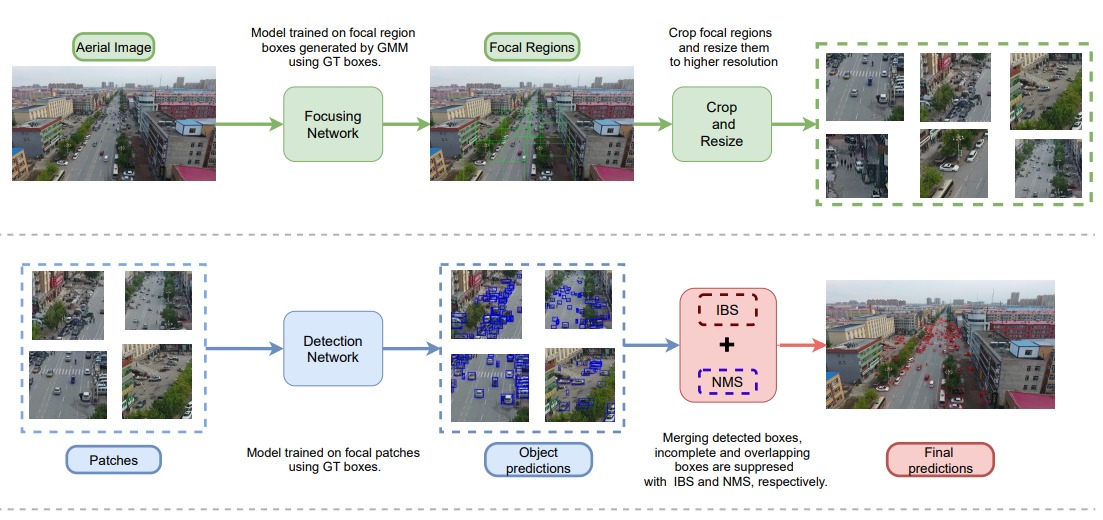
AObject detection performance on aerial images are hindered by the small objects, changes in the perspective of objects, occlusion and truncation. Using high resolution images as input is one of the simplest solutions to the small object detection problem. Unfortunately, high-resolution images impose an unaffordable computational cost to deep neural networks. Using a focusing mechanism and increasing the resolution of the focal regions have the advantages of this simple method, but at lower computational cost. Focus&Detect consists of two components : (1) Focus network; (2) Detection network. While focus network detects the possible object containing regions (Focal Regions), detection network detects objects in these focal regions. Final predictions are generated by merging the predictions of focal regions. NMS and IBS methods are applied to eliminate overlapping and truncated boxes. Both detectors are trained with supervision. Focus network utilizes cluster coordinates generated by a Gaussian Mixture Model as supervision signal. On the other hand, detection network utilizes object ground truth bounding boxes in each respective focal region.
Model Compression
Deep learning methods outperform traditional methods on problems of the computer vision field. However, these methods require high computational cost, process time and memory, since they consist of large numbers of parameters. Using these methods is impossible on devices with low-budget and real-time applications. Hence, model compression has become an emerging topic, which aims to decrease the costs while achieving the least loss of performance. In this scope, we are trying to develop novel model compression methods and examine them both theoretically and practically.
In our study, we focus on knowledge distillation which is one of the model compression techniques. It basically means transferring knowledge from teacher models to student models. In our work, PURSUhInT: In Search of Informative Hint Points Based on Layer Clustering for Knowledge Distillation, we propose a method for determining efficient hint positions that teacher's knowledge is taken from. For this purpose, we obtain clusters of layers from pretrained teacher models and select one representative layer for each cluster as hint positions in order to avoid redundancy in terms of layers' knowledge.
Digital Pathology
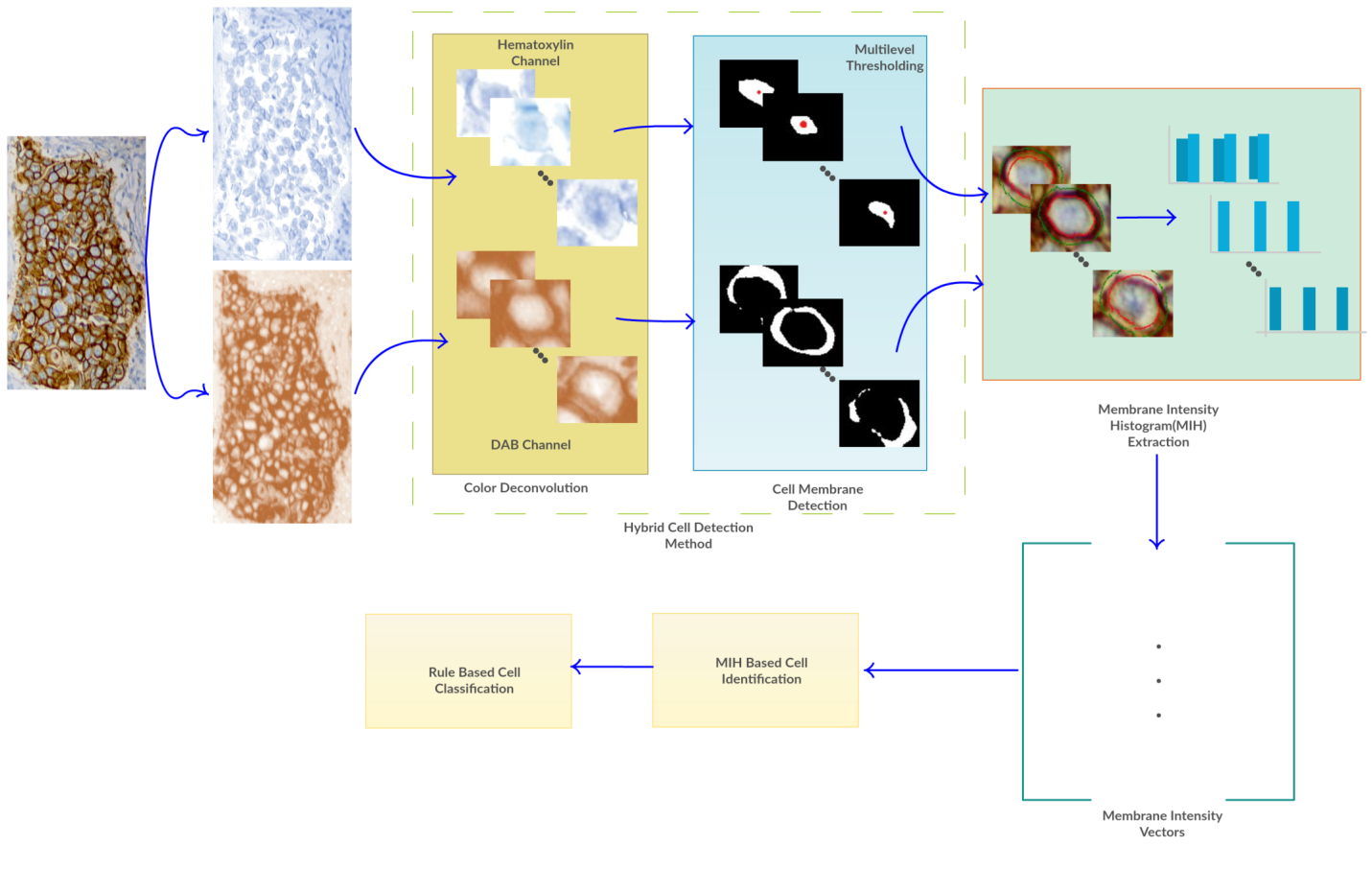
We analyze tissue samples on a cellular basis where each cell is identified using
membrane-based feature extraction and classification methods. Important research on
this topic is myelin qualification in fluorescent microscopic images. Myelin sheath,
wrapped around axons, allows rapid neural signal transmission, and degeneration of
myelin causes various neurodegenerative diseases, such as Multiple Sclerosis (MS).
For candidate drug discovery, it is essential to quantify myelin. This requires
tedious expert labor comprising myelin labeling on microscopic fluorescence images,
usually acquired by confocal microscopes. Detecting and quantifying myelin by using
machine learning is the aim of this project.
Our poster on calcium signaling analysis for
ALS diagnosis.
Compressed Domain Video Analysis

This project proposes a Markov model and wavelet transform-based technique to further
improve the current state-of-the-art methods for video smoke detection by detecting
signs of smoke existence in the MJPEG2000 compressed video. Existing video-based
methods have been developed for the analysis of uncompressed Spatio-temporal
sequences and are not appropriate for compressed video formats. Working with
compressed video formats reduces the number of coefficients makes it suitable for
parallel processing and paves the way for real-time processing which brings
technical improvement in the field of video analysis. The proposed method is an
appropriate alternative for traditional detection methods such as point and
volumetric detectors and some of the computer vision-based approaches. For instance,
point detectors do not help in large and spacious covered places; in the same manner
of disadvantage, volumetric detectors issue an alarm when they «see» smoke within
their viewing ranges. The proposed method has been applied on mostly home-made
sequences as an initial result, and it will be carried out on the larger dataset in
further works.
A presentation on smoke detection
given at Purdue University.
Hyperspectral Data Analysis / Compression
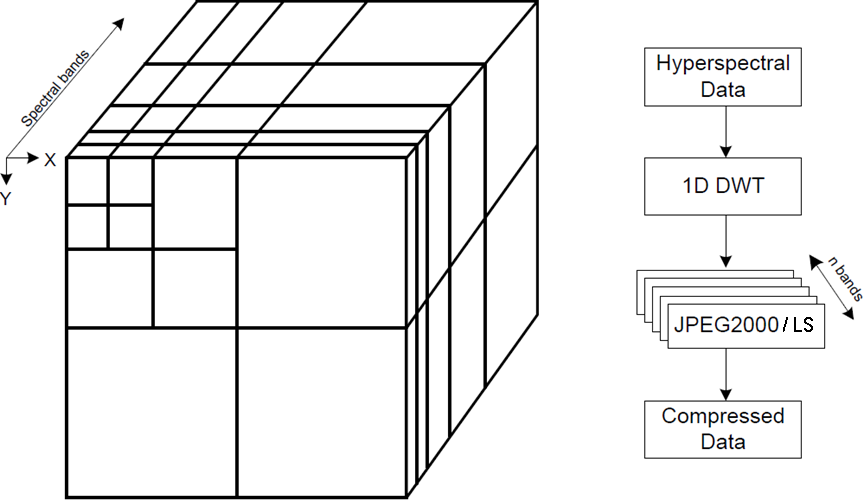
We develop algorithms to compress hyperspectral images using tools such as discrete
wavelet transforms and graph signal processing. Hyperspectral images are images
volumetric images with composed of a continuous bands with diferent wavelengths. In
our research, we have developed ways to comress the images using different
techniques such as appying different vavelets with lookup tables and graph singal
processing.
Our poster on hyperspectral image
compression.
Our poster on smoke detection from H264
compressed videos.
Continual Learning
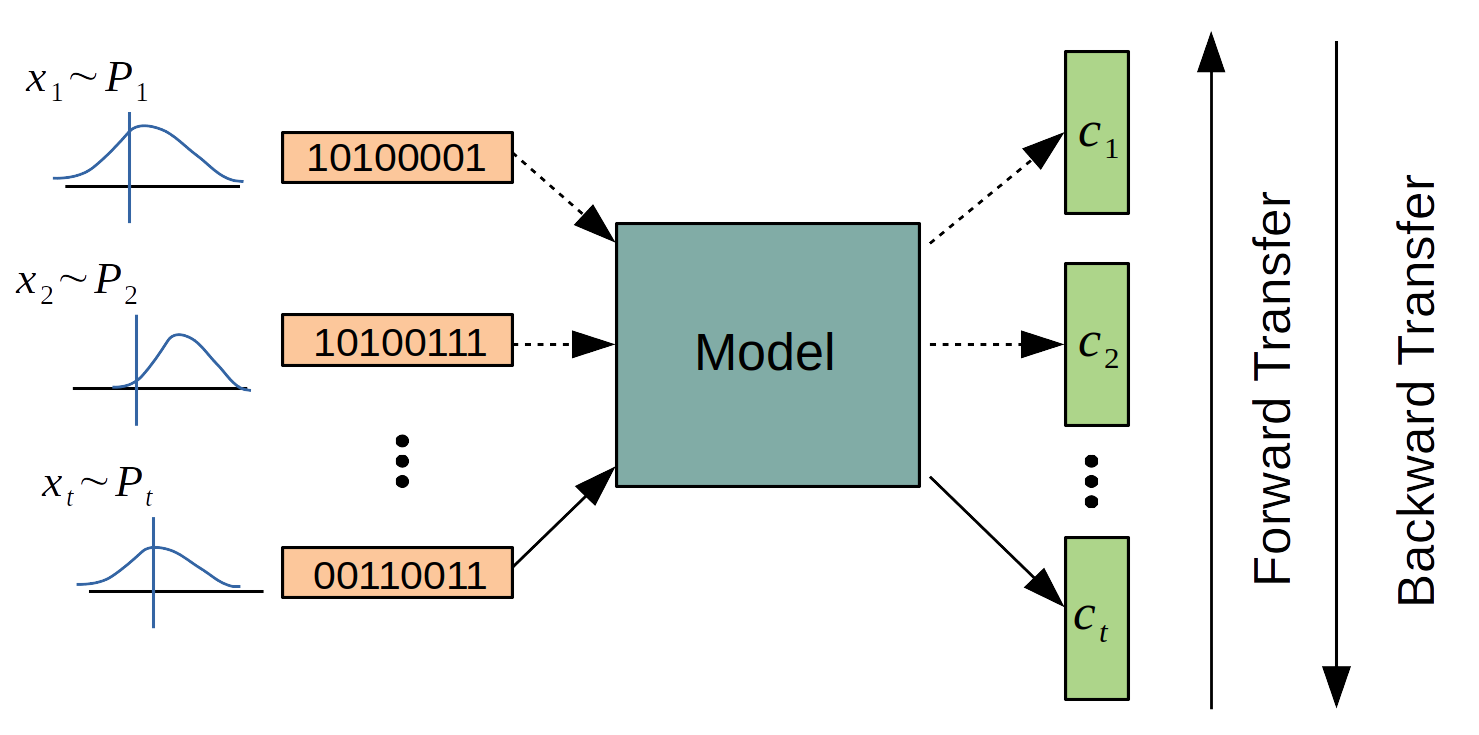
Artificial Neural Networks are addressing major problems of computer vision, natural language processing, and data science in the last decade with increasing computational power and amount of data. Despite its popularity and success, when presented with a sequence of tasks with only having access to the current task's data, neural networks fail to preserve their performance on previously learned tasks. This problem is called catastrophic forgetting and one of the biggest obstacles on the way of artificial general intelligence. The purpose of continual learning is to be able to learn a sequence of tasks without suffering from catastrophic forgetting while improving forward and backward transfer across tasks.